
DeepSeek V4 เปิดตัว — โมเดล open-source ที่อ้างว่าปิดช่องว่างกับ frontier models ได้แล้ว
DeepSeek เพิ่งเปิดตัว DeepSeek V4 เมื่อ 24 เมษายน 2026 แบ่งเป็นสองรุ่น: V4-Pro (1.6 ล้านล้าน parameters, active 49B ต่อ token) และ V4-Flash (284B parameters, active 13B) ทั้งคู่รองรับ context ยาว 1 ล้าน tokens และเปิด weights ภายใต้ MIT license
จุดเด่นคือ performance ใกล้เคียง frontier models อย่าง GPT-5.5 และ Claude Opus แต่ราคา API เริ่มต้นแค่ $0.14 ต่อล้าน input tokens สำหรับ V4-Flash ซึ่งถูกกว่าคู่แข่งหลายเท่า
ถ้า benchmark ที่ DeepSeek อ้างพิสูจน์ได้จริงในการใช้งานจริง มันจะเปลี่ยน landscape ของ AI market ไปเลย เพราะทำให้ทีมเล็กๆ เข้าถึง advanced AI ได้ง่ายขึ้นมาก
ภาพรวมโมเดลใหม่
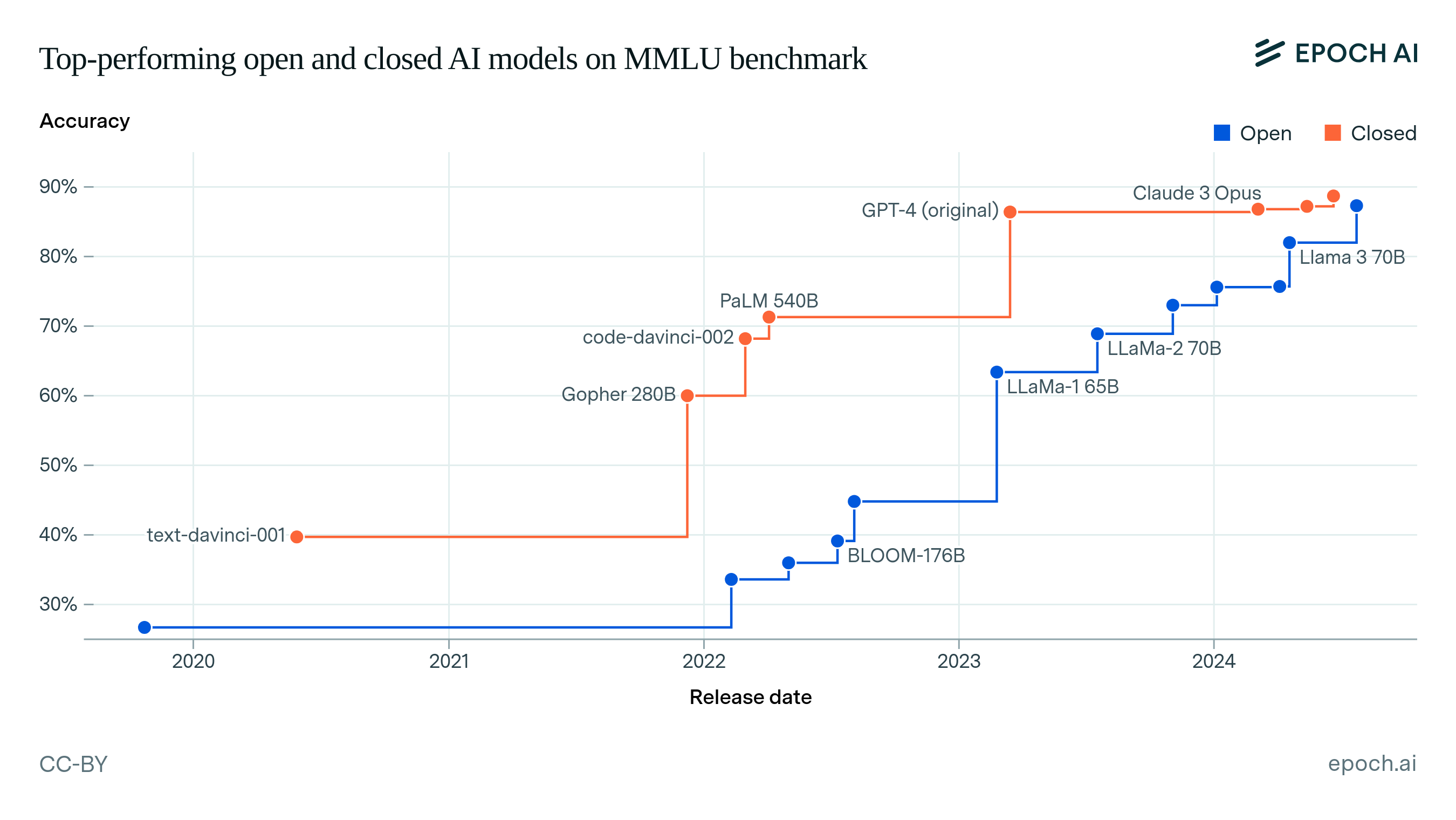
DeepSeek V4 ใช้สถาปัตยกรรม Mixture-of-Experts (MoE) เหมือนรุ่นก่อน แต่เพิ่ม hybrid attention ใหม่ที่ผสม Compressed Sparse Attention (CSA) กับ Heavily Compressed Attention (HCA) ทำให้ใช้ FLOPs แค่ 27% และ KV cache แค่ 10% เทียบกับ V3.2 ในโหมด context ยาว
การ train ใช้ข้อมูล 33 ล้านล้าน tokens และเปลี่ยนมาใช้ Muon optimizer แทน AdamW พร้อม FP4 quantization-aware training สำหรับ expert weights ทำให้ได้โมเดลที่ทั้งแรงและประหยัดทรัพยากรในเวลาเดียวกัน
สิ่งที่น่าสนใจคือ DeepSeek สามารถ scale ขึ้นไป 1.6 ล้านล้าน parameters ได้โดยยังคงราคา API ไว้ระดับที่ startup เข้าถึงได้ แสดงให้เห็นว่า optimization techniques ของพวกเขาก้าวหน้ามากจริงๆ
เมื่อ AI ราคาแพงเป็นอุปสรรคในการทำงาน

หลาย startup ไทยต้องหยุดโปรเจค AI เพราะค่า API แพงเกินรับไหว โดยเฉพาะ frontier models ที่กิน token เยอะ บางทีมต้องใช้โมเดลถูกกว่าแทน แม้ว่าผลลัพธ์จะไม่ค่อยดีนัก
นักวิจัยมหาลัยก็เจอปัญหาเดียวกัน งบวิจัยแค่แสนสองแสนต้องเลือกระหว่างทำ experiment น้อยๆ กับโมเดลดี หรือทำเยอะแต่ใช้โมเดลกลางๆ บางคนเลยเปลี่ยนไปใช้ open-source models แทน ถึงจะต้องมา fine-tune เอง
เรื่องราคานี่เป็น bottleneck ใหญ่จริงๆ ที่ทำให้หลายไอเดียดีๆ ไม่ได้เกิดขึ้น เพราะทีมเล็กๆ เข้าไม่ถึงเทคโนโลยีระดับ frontier
ตำแหน่งในแผนผลิตภัณฑ์ของ DeepSeek
DeepSeek V4 มาแทนที่ V3/V3.2 ในฐานะ flagship model ของค่าย โดยแบ่งเป็น 2 tier ชัดเจน: V4-Pro สำหรับงานหนักที่ต้องการ reasoning ระดับสูง และ V4-Flash สำหรับงานทั่วไปที่เน้นความคุ้มค่า
ตอนนี้ DeepSeek เตรียม deprecate API เดิม (deepseek-chat และ deepseek-reasoner) ภายในวันที่ 24 กรกฎาคม 2026 ซึ่งบ่งบอกว่า V4 จะเป็น platform หลักของค่ายไปข้างหน้า ทั้งสองรุ่นรองรับ dual mode คือ Thinking และ Non-Thinking ในตัว
การมีทั้ง Pro และ Flash ดีมากสำหรับ developer เพราะเลือกใช้ตามงบและความต้องการได้ ไม่จำเป็นต้องจ่าย premium ทุกครั้ง
เปรียบเทียบกับรุ่นก่อน
| Factor | DeepSeek V4-Pro | DeepSeek V4-Flash | DeepSeek V3 |
|---|---|---|---|
| Parameters (total/active) | 1.6T / 49B | 284B / 13B | 685B (dense MoE) |
| Context Length | 1M tokens | 1M tokens | 128K tokens |
| SWE-bench Verified | 80.6% | — | — |
| LiveCodeBench | 93.5 | — | — |
| API Input Price | $1.74/1M | $0.14/1M | — |
กระโดดจาก V3 มา V4 ชัดเจนในทุกมิติ: context ยาวขึ้น 8 เท่า (128K → 1M tokens), V4-Pro มี parameters รวม 1.6 ล้านล้านตัวแต่ active แค่ 49B ต่อ token ทำให้ inference เร็วกว่าที่คิด
V4-Pro-Max ทำ SWE-bench Verified ได้ 80.6% ใกล้เคียง Claude Opus 4.6 ที่ได้ 80.8% และ LiveCodeBench สูงถึง 93.5 ซึ่งเป็นคะแนนสูงสุดในบรรดาโมเดลทั้งหมดที่เคยทดสอบ
ความสามารถที่ใช้ได้จริงในชีวิตประจำวัน
การเขียนโค้ดและ debugging — V4-Pro-Max ได้ Codeforces Rating 3206 และ GPQA Diamond 90.1% แสดงให้เห็นว่าเขียนโค้ดและแก้ปัญหาซับซ้อนได้จริง ไม่ใช่แค่ตัวเลข benchmark สวยๆ
วิเคราะห์ข้อมูลและ reasoning — MMLU-Pro ได้ 87.5% แสดงว่าเข้าใจเนื้อหาเชิงลึกหลายสาขา ตั้งแต่วิทยาศาสตร์ไปจนถึง business analysis
Context ยาว 1M tokens — อ่านเอกสารยาวๆ ได้ทั้ง codebase หรือ report หลายร้อยหน้าในครั้งเดียว โดย attention mechanism ใหม่ทำให้ไม่ต้องแลก speed กับ context length
จุดแข็งอยู่ที่การผสมผสานทักษะหลายอย่างในงานเดียว เช่น อ่าน codebase ทั้งหมดแล้ว debug ได้ในคราวเดียวเพราะ context กว้างพอ
เปรียบเทียบกับคู่แข่งตัวจริง
| Factor | DeepSeek V4-Flash | DeepSeek V4-Pro | GPT-5.5 | Claude Opus 4.6 |
|---|---|---|---|---|
| ราคา API (input) | $0.14/1M | $1.74/1M | $2.50/1M | $15/1M |
| ราคา API (output) | $0.28/1M | $3.48/1M | $10/1M | $75/1M |
| Context Length | 1M | 1M | 400K | 200K |
| SWE-bench | — | 80.6% | — | 80.8% |
| Open Source | MIT | MIT | Closed | Closed |
จุดแข็งที่ชัดที่สุดคือราคา V4-Flash ที่ output token ราคาแค่ $0.28/M เทียบกับ Claude Opus ที่ $75/M — ถูกกว่ากว่า 250 เท่า แม้แต่ V4-Pro ก็ยังถูกกว่า Opus ราว 21 เท่า
ส่วน context ยาว 1M tokens ก็เหนือกว่าทุกค่าย และที่สำคัญคือเปิด weights ภายใต้ MIT license ทำให้ deploy บน infrastructure ของตัวเองได้ ไม่ต้องพึ่ง API ของใคร
สำหรับบริษัทไทยที่งบจำกัด V4-Flash คือจุดเริ่มต้นที่ดีมากเพราะทดลองได้โดยไม่ต้องกลัวค่าใช้จ่ายบานปลาย
จุดแข็งและข้อจำกัดที่ควรรู้
ข้อดีที่เด่นชัด: ราคา output token ถูกกว่า Claude Opus ถึง 21 เท่าในระดับ V4-Pro และถูกกว่า 250 เท่าในระดับ V4-Flash ทำให้บริษัทไทยเข้าถึง frontier-level AI ได้ง่าย context 1M tokens เปิดโอกาสใช้งานที่เดิมทำไม่ได้ และ MIT license ทำให้ self-host ได้เต็มที่
ข้อจำกัดที่ต้องรู้: ภาษาไทยยังไม่แข็งแกร่งเท่า GPT-5.5 หรือ Claude ตอบคำถามเฉพาะทางภาษาไทยได้แต่อาจไม่ละเอียดเท่า เนื่องจาก DeepSeek เป็นบริษัทจีน training data ภาษาไทยอาจไม่มากเท่าค่ายตะวันตก และ V4 ยังเป็น preview ยังไม่ชัดว่า production stability จะเป็นอย่างไร
สำหรับงานทั่วไปภาษาอังกฤษ DeepSeek V4 คุ้มมาก แต่ถ้าต้องใช้ภาษาไทยหนักๆ ควรเตรียม fallback plan ไว้
ค่าใช้จ่ายที่ซ่อนอยู่
แม้ DeepSeek V4 จะดูถูกกว่าคู่แข่ง แต่ต้นทุนที่ซ่อนอยู่อาจทำให้งบโปรเจคพุ่งได้ ถ้าเลือก self-host V4-Pro ที่ 1.6T parameters จะต้องใช้ GPU cluster ขนาดใหญ่ ซึ่งอาจแพงกว่าใช้ API ถ้า traffic ไม่สูงพอ
API rate limiting อาจบังคับให้อัพเกรด plan เร็วกว่าที่คิด โดยเฉพาะถ้าใช้ในระบบ production ที่มี traffic สูง และเนื่องจาก API เดิมจะ deprecate ในเดือนกรกฎาคม 2026 ทีมที่ใช้ V3 อยู่ต้องเตรียม migrate
ก่อนเริ่มโปรเจคใหญ่ ควร pilot test ก่อนสัก 1 เดือน คิด total cost of ownership รวมถึง migration cost จาก V3 ไม่ใช่แค่ดูราคา API per token
ใครควรเลือกใช้ DeepSeek V4
เหมาะสำหรับ: สตาร์ทอัพที่ต้องการ AI performance ระดับ frontier แต่งบจำกัด โดยเฉพาะ V4-Flash ที่ $0.14/M input tokens ถูกสุดในตลาด นักวิจัยที่ทำ experiment ระยะยาวก็ได้ประโยชน์จากราคาถูกในการรัน inference จำนวนมาก และทีมที่ต้องการ self-host ภายใต้ MIT license
ไม่เหมาะสำหรับ: enterprise ที่ต้องการ 24/7 support แบบพรีเมียม เพราะ ecosystem ยังไม่เท่า OpenAI หรือ Anthropic บริษัทที่ strict เรื่อง data compliance อาจมีข้อจำกัดเรื่อง data residency เนื่องจาก DeepSeek เป็นบริษัทจีน
ถ้าเป็น MVP หรือ proof of concept แนะนำให้ลอง V4-Flash ก่อน เพราะราคาถูกมากจน fail fast ได้ไม่เจ็บตัว
บทสรุป: คุ้มค่าหรือรอรุ่นหน้า
DeepSeek V4 เป็น open-source model ที่น่าจับตามากที่สุดในปี 2026 ด้วย benchmark ที่เฉียด Claude Opus (SWE-bench 80.6% vs 80.8%) แต่ราคาถูกกว่าหลายสิบเท่า context ยาว 1M tokens และ MIT license ที่ให้ self-host ได้
สำหรับ dev ไทย แนะนำให้เริ่มจาก V4-Flash สำหรับงานทั่วไป แล้ว upgrade เป็น V4-Pro เฉพาะงาน reasoning หรือ coding ที่ต้องการคุณภาพสูงสุด ส่วนองค์กรใหญ่ควร pilot test ก่อน โดยเฉพาะงานภาษาไทยที่ยังต้องเทียบกับ GPT-5.5 เป็นรายกรณี
แนวโน้ม 2026 จะเห็น Chinese AI models แข่งดุขึ้นอีก ทำให้ market มี choice มากขึ้นและราคาถูกลง DeepSeek V4 เป็นหลักฐานชัดเจนว่า open-source กำลังไล่กวด closed-source อย่างจริงจัง